Generalization by asking! How can prompt engineering be the gateway to zero-shot generalization?
09 Dec 2021 |We’re in an exciting time when it comes to Natural Language Processing (NLP) models. Large language models, which are text generation models such as GPT-3 [1], are excelling at various NLP tasks, from summarizing text, to answering questions, to text comprehension and inference. The success of GPT-3 traces back to the massive scale of the model with over 175 billion parameters and the sheer volume of data that was used to train it…
Let’s take a look at a few examples posted by OpenAI.
The first example is to correct the grammar of a given sentence
Input
Original: She no went to the market. Standard American English:
Sample Response
She didn’t go to the market.
Cool, the model produced a grammatically correct version of the sentence! Let’s see a more complex example, such as text summarization
Input
A neutron star is the collapsed core of a massive supergiant star, which had a total mass of between 10 and 25 solar masses, possibly more if the star was especially metal-rich.[1] Neutron stars are the smallest and densest stellar objects, excluding black holes and hypothetical white holes, quark stars, and strange stars.[2] Neutron stars have a radius on the order of 10 kilometres (6.2 mi) and a mass of about 1.4 solar masses.[3] They result from the supernova explosion of a massive star, combined with gravitational collapse, that compresses the core past white dwarf star density to that of atomic nuclei.
tl;dr:
Sample Response
A neutron star is a star that is so dense that it has collapsed into a sphere the size of a city.
The input in this case is a paragraph from the Wikipedia page of a neutron star and the output is a summary of that paragraph. What is interesting is that the generated output compared the size of the neutron star to that of a city. Does the model understand that a 10 kilometer radius is approximately the size of a city? While passage comprehension is an interesting problem, we will be focusing on another aspect of language models.
Notice in the previous examples, the input ends by specifying the task we want the model to perform. Specifically the commands Standard American English: and tl;dr: are inserted at the end of the text passage such that it triggers the task wanted.
Recently, a new style of work is emerging, where it is not about making models larger and deeper, but rather focus on the data side where you “ask” the model to do the task you want. Well, how do you ask? There is a polite way of doing it, prompt engineering!
In this blogpost, I will be going through HuggingFace’s T0 model, where they show how T0 can outperform OpenAI’s GPT-3 on a number of NLP tasks while still being 16x smaller.
Why T0?
With the recent advances of natural language processing, we witness a new era of generalized models. How did this generalization come to be? One explanation of this phenomenon can be that large language models generalize as a result of an implicit process of multitask learning [4]. In other words, learning to predict the next word entails learning a mixture of implicit tasks within the pre-training corpus. You can imagine that if the data is sourced from a public forum, the model learns the style of question answering inherently from the data. T0 explores the idea of explicit multitask training [6]. But why do we want to explicitly train models? We all know that the computational resources required to train a model with capacity as large as GPT-3 is intractable. The question is, if we use explicit training on NLP tasks can we perform similarly (or even better) without the need for a large amount of parameters? This is exactly the question targeted by the paper “Multitask Prompted Training Enables Zero-Shot Task Generalization”
What is T0?
The zero in the name T0 comes from “zero-shot” generalization. Actually, T0 is a fine-tuned version of Google’s T5, which is an encoder-decoder model trained on a wide range of supervised tasks [5]. There are more subtle differences between the two models, since T5 is a text-to-text framework trained on filling masked tokens from the input, the authors in [2] modify it to become a conditional text generator. The magic behind T0 is mainly driven by engineering prompts to be closer to natural language and be of a question style. To make this more concrete, let’s see how T5 processes input with respect to various tasks and how it compares to T0.
Figure 1 illustrates an example of a summarization task in T5 and T0 respectively. Notice how in T5 we prefix (highlighted text) the task before providing the text passage. On the other hand, T0 treats this problem as if you were conversing with another human, and you ask them to summarize the text at the end. In the first example, we can clearly see that T5 needs to define a set of downstream tasks to be handled by the model. If we would like to include new tasks, we probably need to fine-tune the model. As for T0, it follows a natural question-answering type of setting… and based on the title of the paper it generalizes on unseen tasks.
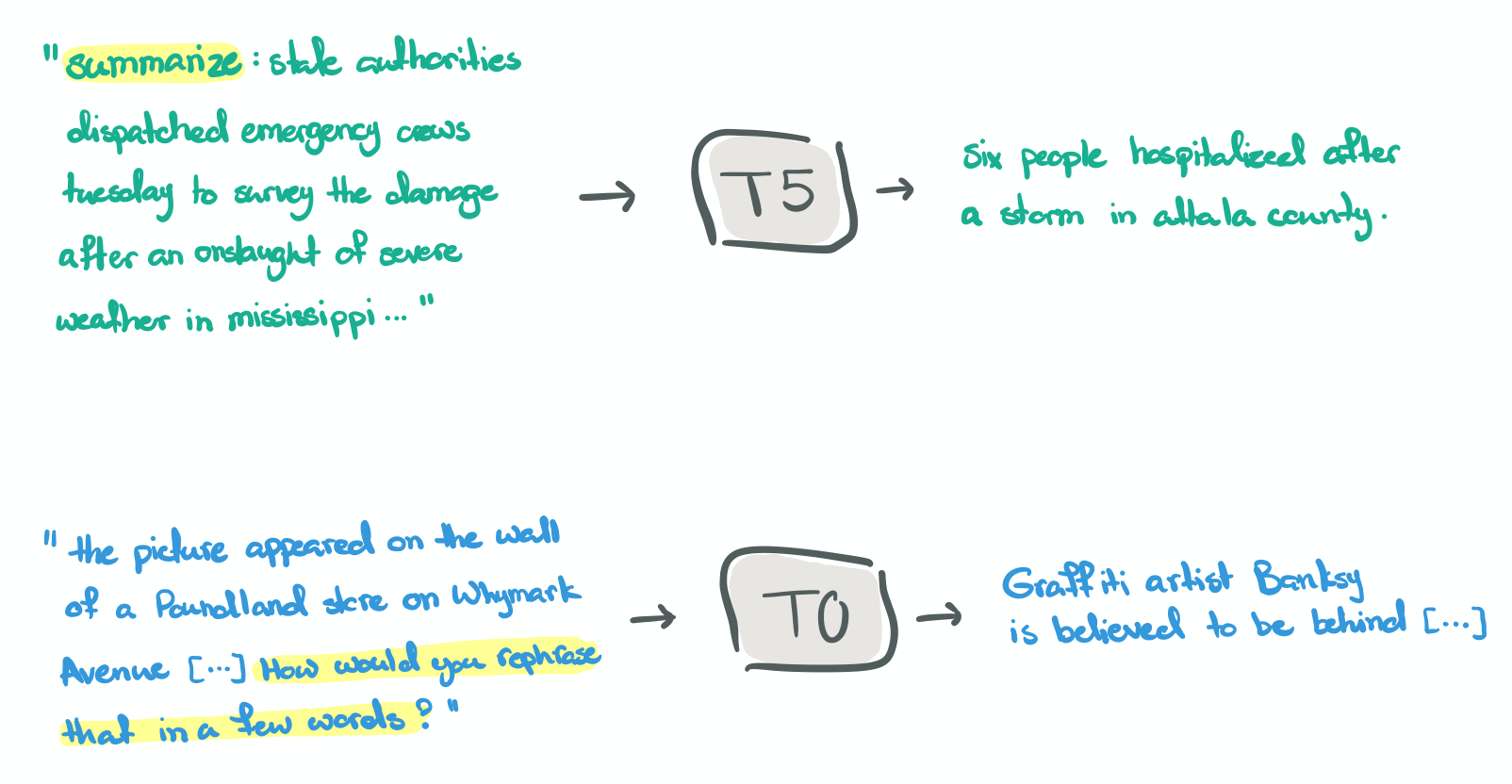
Figure 1: summarization prompts in T5 and T0 models
The paper details the procedure and templates used to convert various labeled NLP task datasets, such as question answering, natural language inference, etc, to prompts of natural structure.
There are many approaches to crafting prompts and there is a lot of work happening in the prompt engineering field. One of the great resources you refer to for this subject is the comprehensive survey [3]. Cohere AI also provides documentation on prompt engineering.
How did T0 convert the supervised datasets?
To transform a large collection of data, the authors used a template based conversion based on the given task. A prompt consists of an input template and target template as showcased in Figure 2. They use the templates to map a data example into natural language for the input and target sequences.
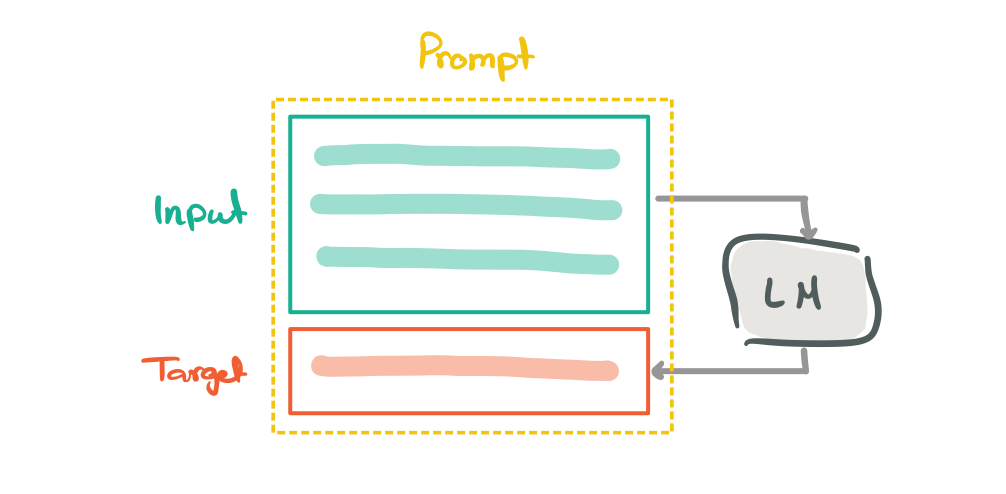
Figure 2: prompts consists of input and target templates
36 contributors collaborated to develop these prompts. The authors encouraged contributors to diversify the templates in order to provide a robust collection of prompts. The main annotation guideline was that prompts needed to be grammatically correct and serves purpose of the task. Going back to the summarization task, Figure 3 illustrates how we can convert the original data into a prompt. In the original dataset, we had two pieces of information, a “document” paragraph and a “summary” paragraph. To make it more natural, we create an input template (green) that inserts the document with additional text to specify the task. As for the target template (orange) it holds the summary paragraph.
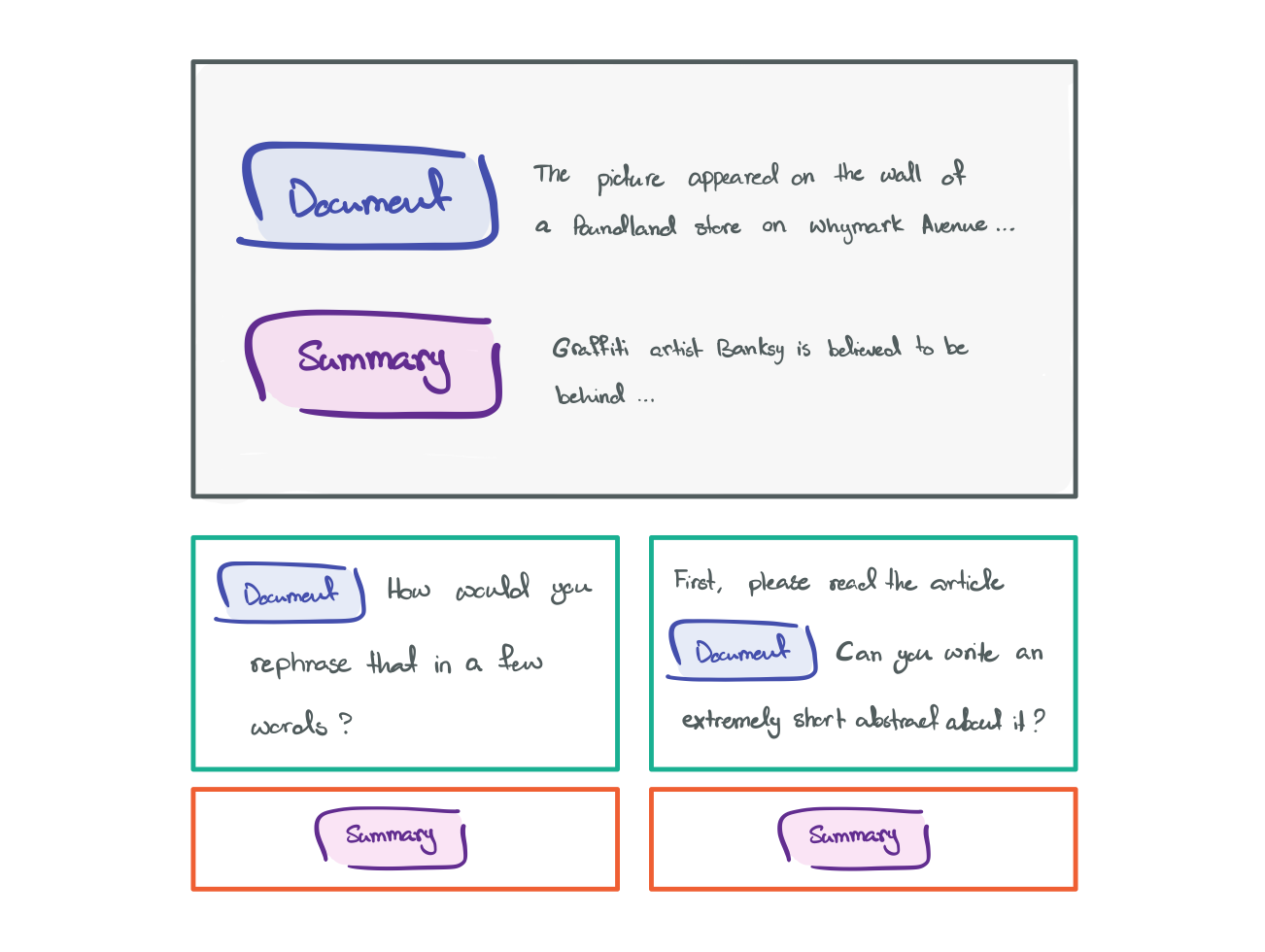
Figure 3: prompt for document summary
To make it more concrete, let’s look at another example, question resolution. Figure 4 illustrates this example where there are two questions and we are trying to figure out if they are the same question. Intuitively, you can think about it as wanting the prompt to be in a conversation format.
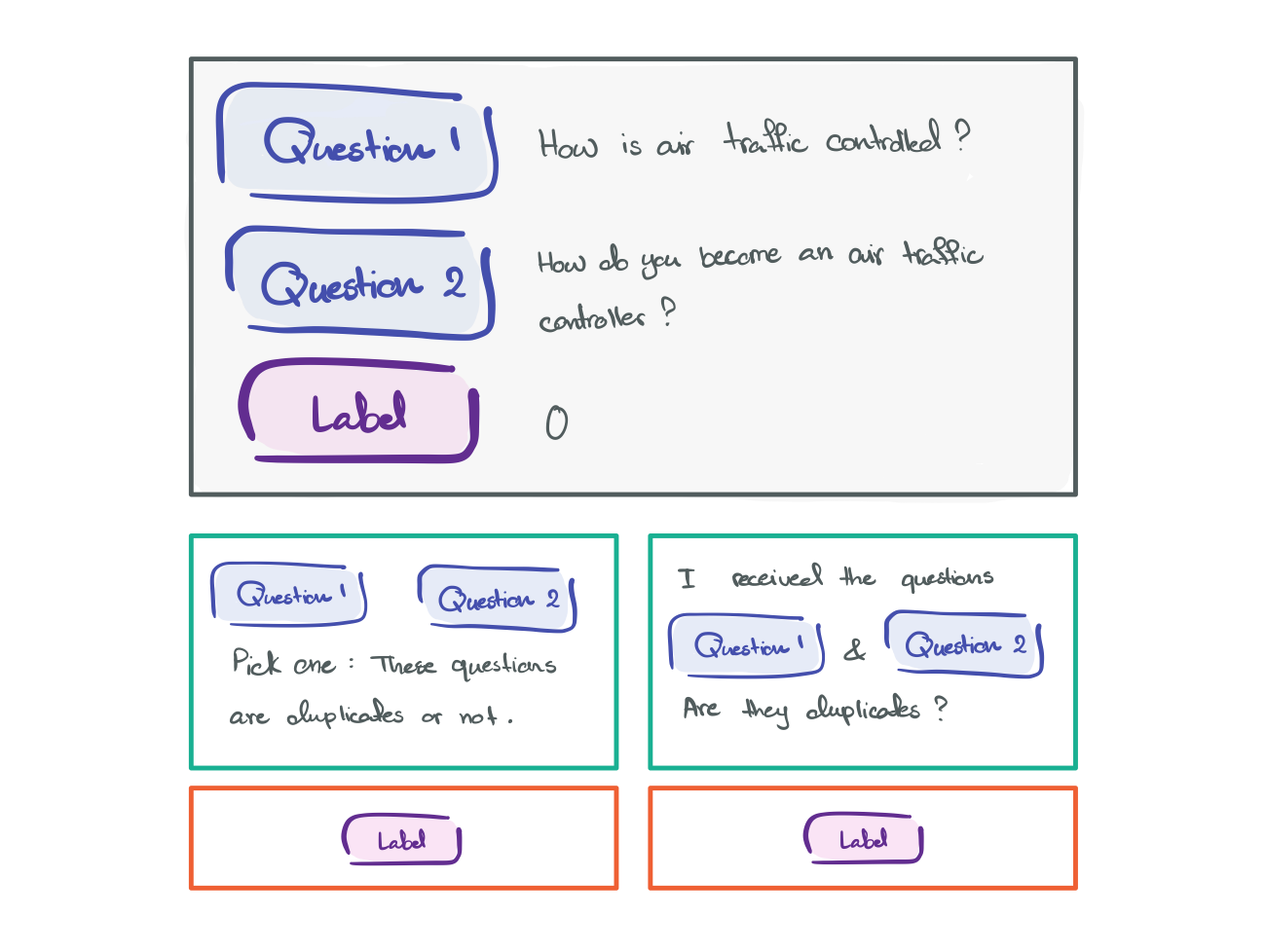
Figure 4: prompt for question resolution
There was a lot of work done to generate these prompts, I recommend referring to the appendix of the paper for more details of the prompting language and tool used.
Does T0 work?
We’ve looked at the main idea behind T0, so does it work? In their experiments, they explore two main questions:
- Does multitask prompted training improve generalization to unseen tasks?
- Does training on a wider range of prompts improve robustness to prompt wording?
Let us go through each one
1. Does multitask prompted training improve generalization to unseen tasks?
The authors compare the T0, T5, and GPT-3 on held-out test datasets. In essence, the results show that T0 surpasses T5 all the time, which is expected since T0 is a fine-tuned version of T5. Moreover, T0 matches or exceeds GPT-3 performance on 9 out of 11 held-out datasets. It is exciting to see that smaller models, T0 – a 11B parameter model, can perform as well as larger models, GPT-3 – a 175B parameter model. That’s nearly 16 times smaller!
2. Does training on a wider range of prompts improve robustness to prompt wording?
The authors test the variability of the performance on the held-out test datasets by looking at the number of training prompts per dataset. They find that training on more prompts per dataset consistently improves the median and decreases the variability of performance on held-out tasks. Training on prompts from a wider range of datasets also generally improves the median but does not decrease the variability.
The full details of the results are in the paper.
Seems like magic is in the data, so what is happening? In the next section, we playaround with some examples and visualize some of the interesting properties about the input data and tie it to the output.
Playground
You’ve reached this far, time to play around with some data. We will be using this colab notebook to visualize how the input influences the generated output. For visualization, we will be using Ecco, which is an open-source library for explainability of transformer language models.
We will look at T5 (you can explore any model you wish including GPT-2, BERT, etc) which and we will see how the input contributes to the output by using saliency maps. Saliency map is an intuitive way to see and evaluate the contribution of each input feature to the output of a model.
Recall that the T5 model is an encoder-decoder model and we specify the task in hand as a prefix to the text input. Let’s pick a simple example from their paper, which is to translate the sentence “That is good.” from English to German. To do that, we first construct our prompt by specifying the task “Translate to German:” and appending the sentence. In the end, our prompt is “Translate to German: That is good.”.
The command in the input sequence is what is mostly contributing to the output we see! Notice how the words of the sentence are on the low spectrum of contributing percentage. Is this an artifact of this example being a running example of the paper? Or does the model genuinely care about the command more than the actual sentence to produce an accurate output?
Let’s try an unseen task. We create an example of summarizing the summary of 6.S898 class!
Interesting! You can see that the contribution of the input is towards (1) the command and (2) the word in the input that the model decides should be part of the output. While this is a property of summarization, we can tell that the model interpreted the task.
Now that we have seen T5 we can try other models, for example its successor T0. Note that in the attached google colab, we will be using GPT-2 as our base model. Originally we were supposed to test T0 but due to it being a large file (41GB to download) we will replace it with GPT-2. You can try any other language model with a conditional generation property.
Let’s try the “just ask” methodology in prompting language models. If we look at prompts with different styles:
- prompt = “Translate to German: That is good.”
- prompt = “How do you say “That is good.” in German?”
- prompt = “This is good. How do you say it in German?”
What will happen? Let’s see!
task style “Translate to German: That is good.”
question style “How do you say “That is good.” in German?”
question style “This is good. How do you say it in German?”
In the first prompt, we get a sentence completion type of continuations but in the other two prompts, we get an answer from the model, although not for the question we are seeking. In all cases, we can say that the output is not meaningful. This task is probably very hard for the model since, well GPT-2 is nowhere near its successor GPT-3 in terms of generalization capabilities AND it has not seen the type of the prompt before, nor has it seen the task. However it is still interesting to look at how the input and output connect, if you have access to GPT-3 this would be definitely worthwhile to investigate!
That’s it! I hope you enjoyed going through the blog and exploring how prompts can gauge the model output. When T0 gets more compact, this blog will be updated…
[1] Brown et al., Language models are Few-Shot learners. May 2020.
[2] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for Parameter-Efficient prompt tuning. April 2021.
[3] Liu et al., Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. July 2021.
[4] Radford et al., Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[5] Raffel et al., Exploring the limits of transfer learning with a unified text-to-text transformer. 2019.
[6] Sanh et al., Multitask prompted training enables Zero-Shot task generalization. October 2021.